News Centerbarrow
Industry News
NVIDIA Turing GPU architecture diagram leaked, each SM unit is equipped with
2019-05-27 23:15 The author:Administrator
On August 21, NVIDIA finally unveiled a new generation of gaming graphics CARDS in Germany, where it focused on ray-tracing technology. I don't know if you have found it. For the new Turing graphics card, I don't know anything except a name and RT Core. I don't even have a detailed GPU architecture picture. But VideoCardZ did find a picture of the Turing GPU architecture, and we can see some of it.

This is from VideoCardZ
The leaked drawings of the TU102 core are the Quadro RTX 8000, the Quadro RTX 6000 professional card and the RTX 2080 Ti game card. But only the Quadro RTX 8000, the Quadro RTX 6000 professional card USES a full version of the TU102 core, and the RTX 2080 Ti is still incomplete, which is what we know about the tu102-300 core.
The information marked above is "72 groups of SM units, 4608 CUDA units, 576 Tensor cores, 72 RT cores, 32 geometry units, 288 texture units, 96 raster units, 2 channel NVLink". If you calculate this, you still have 64 CUDA units, 8 Tensor units, and 1 RT Core.
From the GPU architecture diagram, there are 6 sets of GPC units, and there are 12 SM units in one set of GPC. However, the leaked images are too thick to be identified in detail, but we can make a bold guess based on the previous Volta architecture and what huang said at the launch.
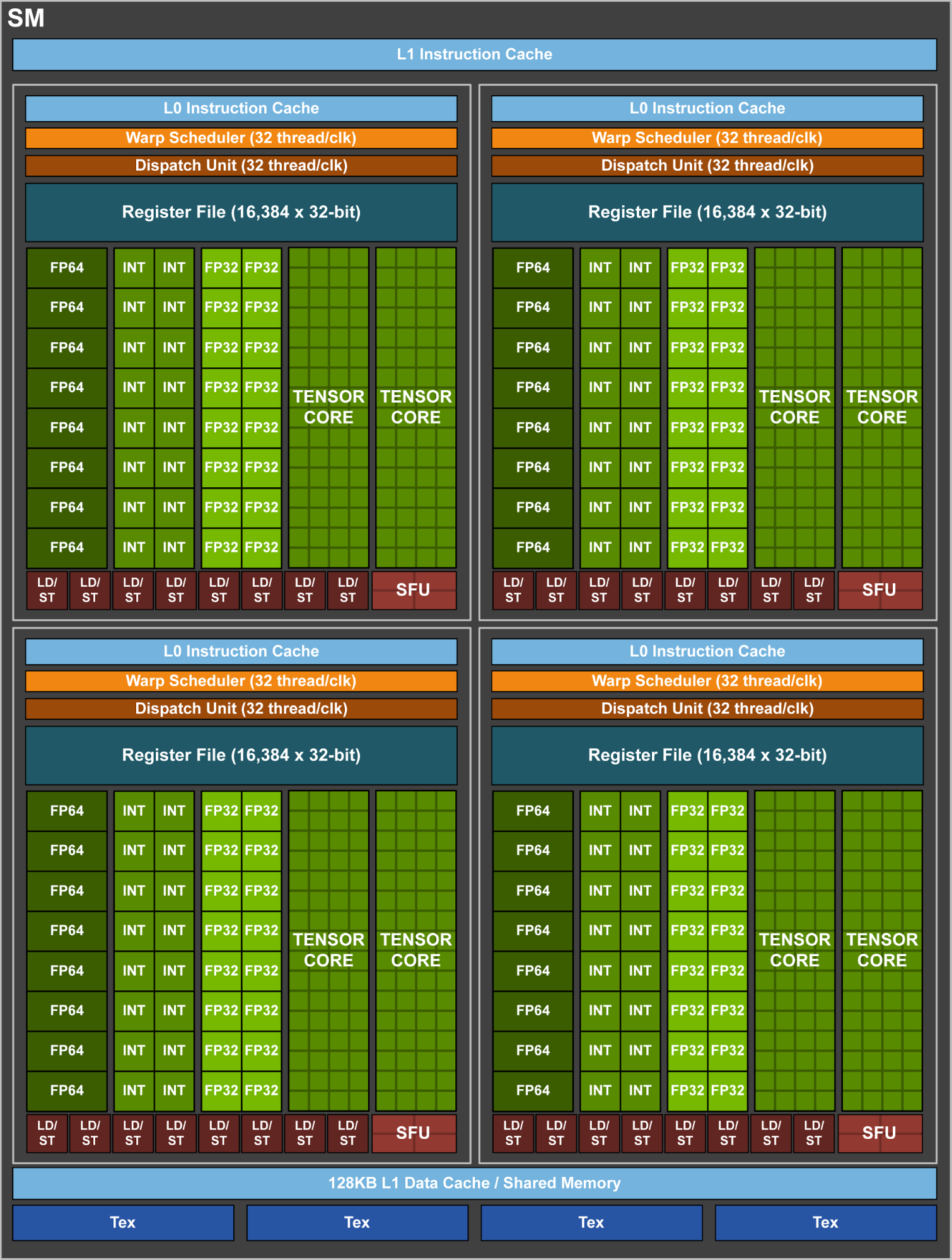
Volta architecture within SM cells
First of all, let's look at the changes in SM units. Originally, there were four units in Volta, namely FP64, INT, FP32 and Tensor Core, but there were only three units in Turing, so FP64 double-precision units were cut off, and the rest were reserved. So where the new RT Core should be, you can see that there's a huge yellow box in the SM cell, highly suspect is RT Core, and the Numbers match the ratio of one SM cell to one RT Core.
In addition, some foreign media said that NVIDIA has doubled the L2 cache Shared by SM units and increased the L1 cache by 1.7 times, which is estimated to enhance the performance of the calculation.

